Internet e World Wide Web
Lezione 04 del corso di Abilità Informatiche (2024/2025)
Sebastian Barzaghi | sebastian.barzaghi2@unibo.it | https://orcid.org/0000-0002-0799-1527 | https://www.unibo.it/sitoweb/sebastian.barzaghi2/
Ipertesto

Termine coniato da Nelson nel 1965, da hyper (“oltre”) e testo.
Ipotizza un sistema in grado di memorizzare documenti e consentire all’utente di costruire percorsi preferenziali e di navigare nella rete informativa costituita dall’insieme di documenti interconnessi.
Cos’è un ipertesto?

Un modo non lineare di presentazione dell’informazione tramite un insieme di unità informative (dette nodi), connesse tra loro da collegamenti (detti link).
Cos’è un ipertesto?
Può essere anche visto come un grafo orientato composto da un insieme di elementi (nodi) collegati tra loro da relazioni (archi) unidirezionali.
Cos’è un ipertesto?

Ha diversi percorsi logici, ciascuno dotato di autonomia di significato.
I percorsi sono scelti a priori dal creatore del documento e a posteriori dall’utilizzatore, in base alla situazione o alle sue personali esigenze.
Elementi principali dell’ipertesto
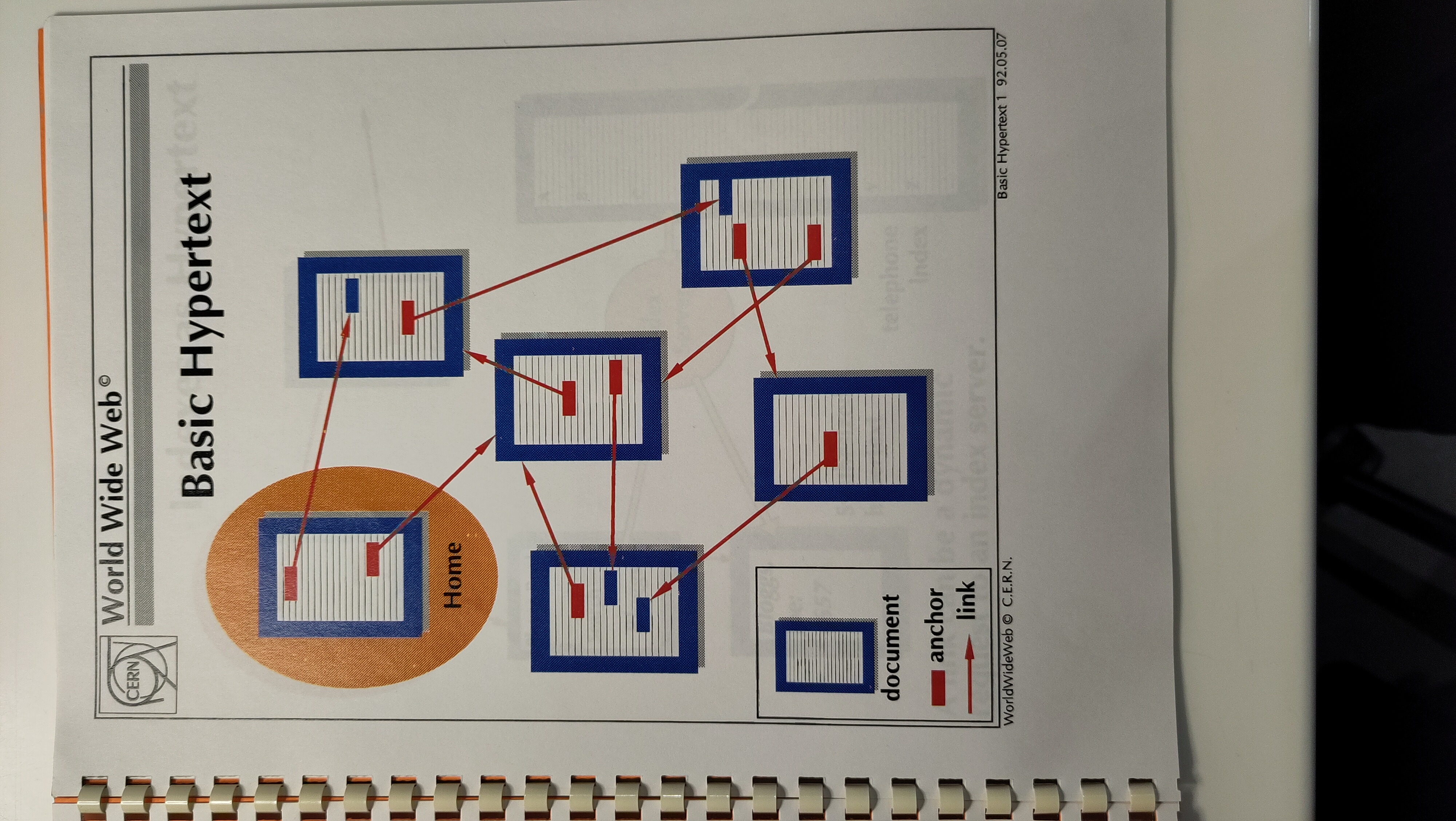
Nodo: unità minima di informazione, dotata di autonomia e completezza;
Ancora: frammento di un nodo da cui un link viene orientato verso un altro frammento di un nodo;
Link: connessione tra una coppia di ancore.
Caratteristiche dell’ipertesto
Granularità: decomponibile in parti più piccole e autosufficienti, dotate di senso, e utilizzabili;
Interattività: dà la possibilità al lettore di rapportarsi non-linearmente con esso;
Integrabilità: estendibile in maniera potenzialmente infinita;
Multimedialità: compresenza di molteplici mezzi di comunicazione differenti.
L’ipertesto ha una lunga storia alle spalle

Ipertestualità - in quanto testualità con struttura reticolare e navigazione non lineare - è sempre esistita (es. note, indici, commenti, sperimentazioni letterarie).
Il Memory extender di Vannevar Bush (‘30)

Concezione moderna (cioè digitale) di ipertesto: un dispositivo teorico impiantato in una struttura a scrivania tramite cui era possibile conservare, annotare, connettere, e leggere documenti registrati su microfilm.
Xanadu di Nelson (1967)

Progetto di creazione di un contenitore per la letteratura mondiale, interconnessa e liberamente disponibile.
Una delle principali fonti di ispirazione per il World Wide Web.
Altro contesto storico
Sistemi ipertestuali di prima generazione (ZOG, Xerox Alto, ecc.);
Dopo il 1983 (anno della messa a disposizione massiva dei personal computer sul mercato): sistemi ipertestuali di seconda generazione (KMS, NoteCards, HyperCard, ecc.);
1987: prima conferenza internazionale sugli ipertesti.
Fine anni Ottanta: l’ipertesto nel mondo

L’ipertesto è estremamente popolare e testato.
Un fisico trentenne col compito di progettare un sistema di gestione dei documenti dell’istituto di ricerca per cui lavorava trae ispirazione da questa tecnologia, finendo per creare il più ampio, utilizzato e influente sistema ipertestuale di tutti i tempi.
Cos’è Internet?

Una rete di comunicazione tra dispositivi distribuiti a livello globale.
Tecnologie su chui si basa: TCP, IP, DNS, ecc...
Cos’è il World Wide Web?

Un sistema documentale ipertestuale distribuito su Internet.
Tecnologie su chui si basa: HTTP, HTML, URL, ecc...
Il Web e l’Internet non sono la stessa cosa
Il Web è un servizio ospitato da Internet, ideato da Cailliau e Berners-Lee al CERN di Ginevra verso la fine degli anni ‘80 come sistema di gestione e comunicazione di informazioni a distanza fra ricercatori.
1990: prima pagina Web.
1993: rilasciato nel pubblico dominio.
Dopo il 1993: sistema di informazione e comunicazione globale per eccellenza.
Uno sguardo più da vicino
Il Web è costituito da un insieme di documenti ipertestuali (pagine web), ciascuno dei quali può essere collegato ad altri tramite link unidirezionali.
Le pagine sono ospitate da nodi specializzati di Internet detti server web.
Un utente può navigare nella struttura ipertestuale accedendo da un nodo, detto client, usando un apposito tipo di programma, detto browser.
Specifichiamo meglio la terminologia di Internet

L’architettura di Internet è basata sull’interazione continua tra
- Server: programmi (e i computer su cui operano) che servono dati e servizi;
- Client: programmi (e i computer su cui operano) che fanno richiesta di dati e servizi.
E la terminologia del Web?
Uniform Resource Locator (URL): schema di identificazione dei contenuti del Web e la singola stringa che agisce da identificatore univoco di una risorsa Web;
Hypertext Transfer Protocol (HTTP): protocollo usato dai server e dai client per comunicare gli uni con gli altri e per il recupero della rappresentazione di una risorsa Web tramite il suo URL;
Hypertext Markup Language (HTML): linguaggio di marcatura di cui sono composte le pagine web e che permette la rappresentazione di una risorsa Web.
Quindi, cosa permette di fare l’interazione tra Internet e Web?
- Rappresentare risorse tramite documenti ipertestuali (attraverso HTML);
- Mettere a disposizione i suddetti documenti ipertestuali (attraverso server Web);
- Identificarli mediante l’utilizzo di un opportuno identificativo (URL);
- Richiederli mediante l’utilizzo di uno specifico protocollo di comunicazione (HTTP);
- Visualizzarli su un computer (attraverso un client).
Il modello client-server
Architettura di rete in cui un agente - computer o software - (il client) accede ai servizi o alle risorse di un altro agente - computer o software - (il server) attraverso una rete.
Gli agenti
- Client: agente che effettua la richiesta;
- Server: agente che dovrebbe avere informazioni su una risorsa e che risponde alla richiesta.
Nel dettaglio: il client

Un computer o un software che accede a un servizio fornito da un server.
Consente agli utenti di interagire facilmente con un servizio o una risorsa remota (es. sito Web, un server di posta elettronica o un sistema di archiviazione cloud).
Es. il computer che state usando; un browser (Firefox, Chrome, Edge, Safari, ecc.); Applicazioni (Netflix, Dropbox, Gmail, Canva, ecc.); un crawler; sensori incorporati (smartwatch, domotica, ecc.)
Nel dettaglio: il server

Un computer o software che fornisce servizi o risorse ai client, attraverso una rete.
Progettato per eseguire specifiche funzioni di elaborazione e gestione delle risorse.
Es. un server Web ospita un sito Web e lo serve ai client che richiedono di accedere e visualizzare il sito.
I messaggi
- Richiesta: il messaggio mandato dal client al server in cui vengono chieste informazioni riguardo una specifica risorsa indicata da un URL;
- Risposta: il messaggio che il server restituisce al client, che può essere positivo oppure negativo.
Interazione Client - Server: esempio del browser
L’interazione viene avviata tipicamente da una richiesta dell’utente, tramite digitazione nella barra degli indirizzi del browser o per attivazione di un link;
Il browser (client) interpreta il comando come la richiesta da parte dell’utente della pagina web corrispondente all’indirizzo specificato;
Il client codifica la richiesta della pagina secondo determinate specifiche e inoltra la richiesta al server, sfruttando opportunamente l’infrastruttura di rete e i relativi servizi;
Interazione Client - Server: esempio del browser
La richiesta viene instradata e raggiunge il server, che la codifica, la interpreta e cerca di soddisfarla;
Se il server approva la richiesta del client, manda al client una risposta “200 OK”, genera una copia del file corrispondente alla richiesta e la spedisce al client;
Arrivata a destinazione, il client interpreta la copia e la visualizza per l’utente.
Cos’è un Uniform Resource Locator?
- Meccanismo usato dai browser per recuperare risorse pubblicate sul Web;
- Una stringa di testo che identifica (come un codice fiscale) e localizza (come un indirizzo di casa) una risorsa Web.
https://it.wikipedia.org/wiki/Amore_e_Psiche
Cos’è un Uniform Resource Locator?
Ogni volta che, da un proprio dispositivo (un computer, uno smartphone, etc.), si clicca su un link, il dispositivo stesso recupera una copia della risorsa a cui l’URL si riferisce, per poi visualizzarla sullo schermo del dispositivo.
In teoria, un URL valido punta ad un’unica risorsa, la quale può essere una pagina HTML, un documento CSS, un’immagine, ecc.; in pratica, esistono delle eccezioni, come un URL che punta ad una risorsa che non esiste più o che è stata spostata.
Un URL come una sorta di codice postale

URL: lo schema

Lo schema (scheme) rappresenta il protocollo (l’insieme di regole) per accedere alla risorsa.
~ Servizio postale da utilizzare.
URL: il dominio

Il dominio (domain name) identifica il tipo di entità che possiede il sito web, il servizio o la risorsa specifica a cui si accede.
~ La città dove risiede l’indirizzo a cui inviare il pacco.
URL: la porta
La porta (port) è il numero del punto di contatto virtuale del server.
~ Codice di avviamento postale.
URL: il percorso

Il percorso (path) rappresenta il percorso della risorsa nel server.
~ L’edificio dove il pacco deve essere inviato.
URL: i parametri

I parametri (parameters) rappresentano informazioni operative sulla risorsa (es. filtri in una ricerca a faccette)
~ Informazioni aggiuntive, come il numero dell’appartamento nell’edificio.
URL: l’ancora

{kind=link}
{kind=link}
{kind=link}
L’ancora (anchor) è l’identificativo di una sezione specifica nella risorsa.
~ La persona a cui è intestato il pacco.